L'IA est-elle vraiment capable d'extraire avec précision des données d'urbanisme à partir des règlements de zonage ?
Partie 1 : L'IA est-elle capable d'extraire avec précision des données d'urbanisme à partir des règlements de zonage ?
Les géants de la tech présentent souvent leurs produits d'IA comme des solutions destinées à faciliter la vie et à gagner en efficacité. Mais pour instaurer la confiance dans l'IA, il faut l'aborder de manière critique, en la considérant comme un simple outil. Dans cette série de trois articles, j'explorerai les outils d'IA permettant d'extraire des données d'urbanisme à partir des règlements de zonage, et je vous ferai part de ce qui fonctionne, de ce qui ne fonctionne pas, ainsi que de la manière dont vous pouvez aborder ces technologies avec confiance et un esprit critique.
Introduction
Dans le domaine de l'urbanisme, la lecture des règlements municipaux peut s'avérer extrêmement chronophage. Trouver les articles pertinents, assimiler toute la terminologie juridique, vérifier les autres exigences, dispositions et modifications… tout cela prend du temps !
Afin d'accélérer le processus de recherche d'informations pertinentes dans les règlements municipaux, nous devons nous poser la question suivante : l'IA est-elle capable d'extraire avec précision des données d'urbanisme des règlements de zonage, et quels en sont les risques et les limites ?
Les géants de la tech commercialisent souvent leurs produits d'IA en mettant en avant qu'ils facilitent la vie et améliorent l'efficacité. Mais pour instaurer la confiance dans l'IA, il faut l'aborder de manière critique, en tant qu'outil. En dehors des articles de recherche universitaires, il existe peu de ressources accessibles expliquant le fonctionnement des modèles d'IA. La connaissance de ces outils devrait être plus accessible à tous. Ce blog partage mon parcours d'apprentissage en décomposant des concepts techniques de manière simple et compréhensible. Les sections « Lectures complémentaires » renvoient les lecteurs vers des ressources externes s'ils souhaitent en savoir plus.
Dans cette série de trois articles de blog, je vais passer en revue les outils d'IA permettant d'extraire des données d'urbanisme à partir des règlements de zonage, et vous expliquer ce qui fonctionne, ce qui ne fonctionne pas, et comment aborder ces technologies avec assurance et un esprit critique. Plus précisément : dans quelle mesure les modèles d'IA peuvent-ils être fiables lorsqu'il s'agit de traiter ce type d'informations juridiques, pour lesquelles une grande précision est souhaitable ?
Cet article constitue la première partie d'une série en trois volets :
- Partie 1 – Choisir le modèle d'IA adapté à la tâche : il est essentiel de sélectionner le bon modèle, car le choix de l'architecture d'un modèle LLM a une incidence sur la précision, les performances et les ressources.
- Partie 2 - Indicateurs ! Évaluation de la précision des modèles de langage de grande envergure (LLM) : les deux modèles sélectionnés dans la partie 1 seront testés afin de déterminer dans quelle mesure ils sont capables d'extraire avec précision les données des règlements de zonage.
- Partie 3 - Affinage d'un modèle linguistique à partir des règlements de zonage : le modèle le plus performant de la partie 2 sera affiné à l'aide de données issues des règlements de zonage afin de déterminer s'il est possible d'améliorer encore sa précision.
Partie 1 : Choisir le modèle adapté à la tâche
Le domaine de l'IA est vaste et il existe de nombreux types de modèles. Étant donné que le principal problème à résoudre est l'extraction de texte non structuré (données de zonage) à partir d'un document juridique sous forme de texte (règlement de zonage), l'accent sera naturellement mis sur les modèles de langage génératif (LLM).
Que sont les LLM ? En bref : il s'agit de modèles d'apprentissage automatique capables d'analyser et de générer du texte en langage humain. L'apprentissage automatique est un sous-domaine de l'IA dans lequel les modèles peuvent « apprendre » les schémas des données d'entraînement et tirer des « conclusions » précises sur de nouvelles données (voir l'image ci-dessous). Comme mentionné précédemment, nous devons prendre un texte juridique complexe et en extraire des informations en posant des questions spécifiques. Il s'agit d'une tâche classique de réponse à des questions (QA) en traitement du langage naturel (NLP).
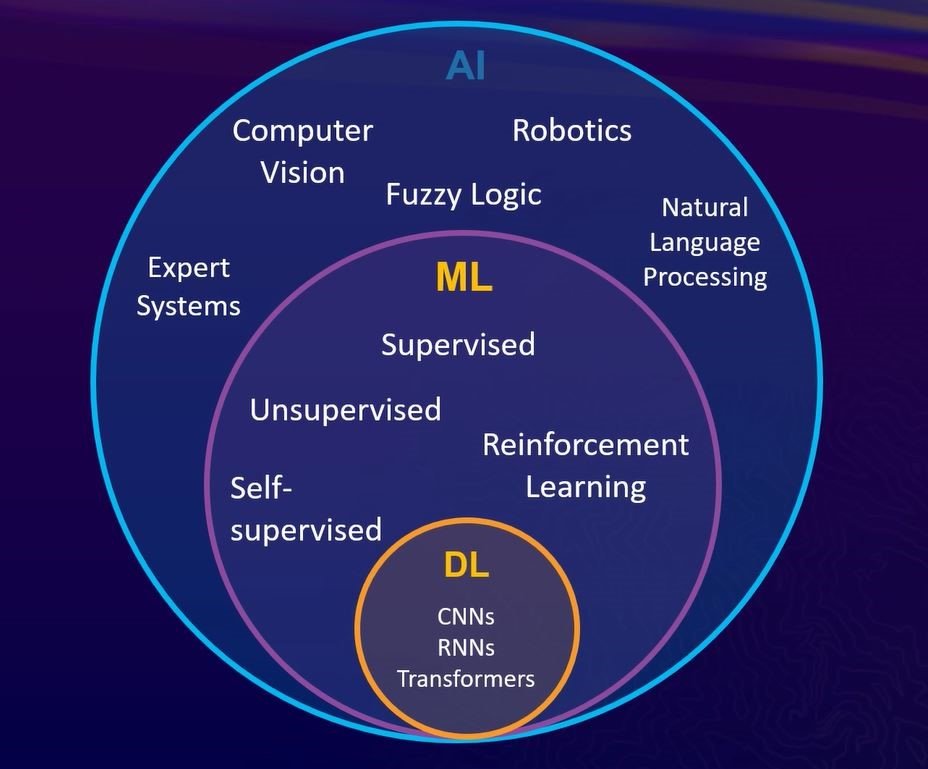
Schéma Esri – Concepts courants dans le domaine de l'IA
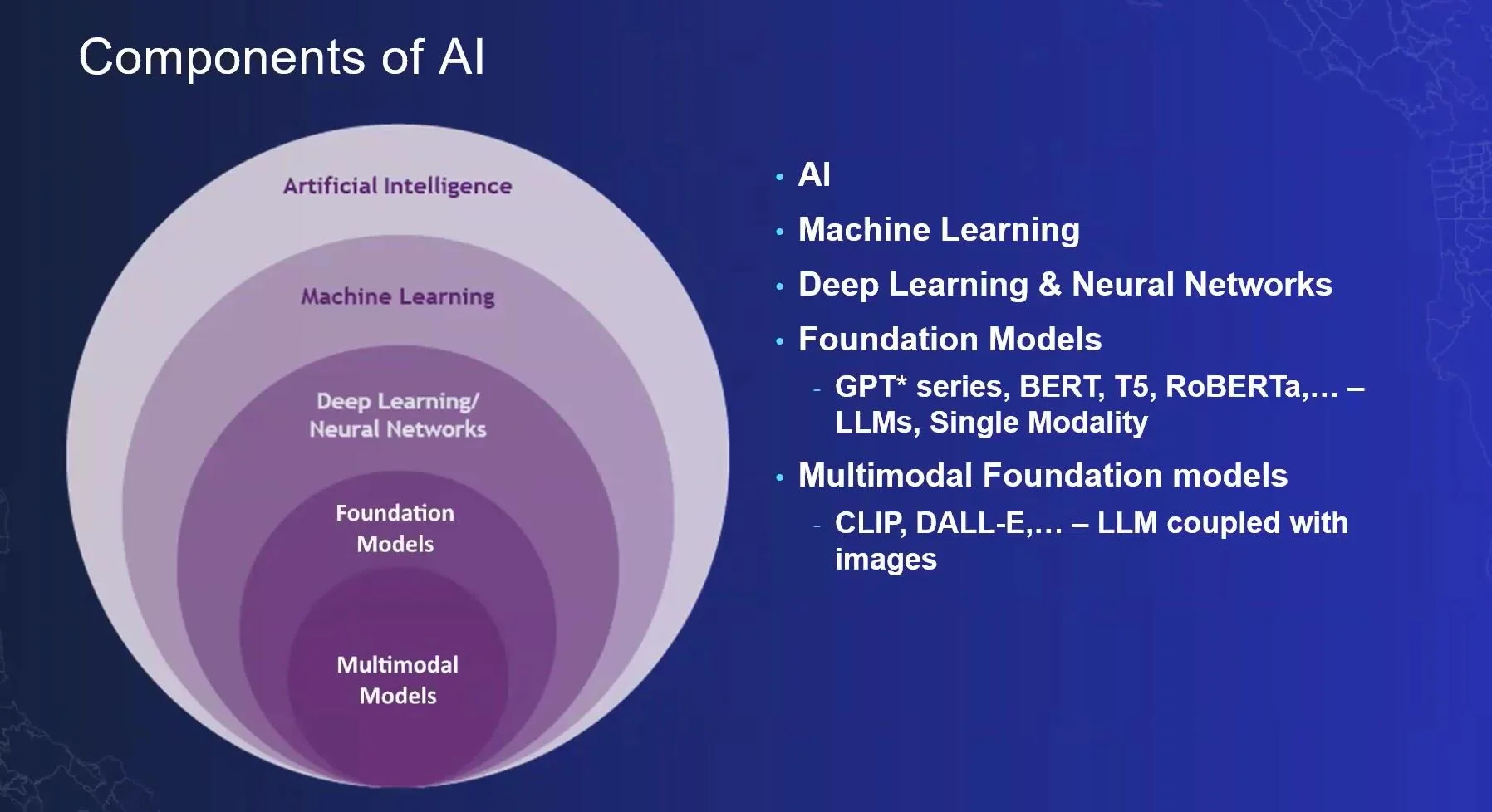
Schéma Esri – Composantes/Domaines de l'IA
Pour en savoir plus :
- IBM - Qu'est-ce que l'apprentissage automatique ?
- IBM - Comprendre les différents types d'intelligence artificielle
Traitement du langage naturel (NLP) VS Grands modèles linguistiques (LLM)
- Traitement du langage naturel (NLP) : « un domaine plus vaste visant à permettre aux ordinateurs de comprendre, d'interpréter et de générer le langage humain. Il englobe de nombreuses techniques et tâches telles que l'analyse des sentiments, la reconnaissance d'entités nommées, la traduction automatique et la réponse à des questions par extraction. » (Hugging Face)
- Modèles linguistiques à grande échelle (LLM) : « Un sous-ensemble puissant de modèles de traitement du langage naturel (NLP), caractérisé par leur taille colossale, leurs vastes ensembles de données d'entraînement et leur capacité à effectuer un large éventail de tâches linguistiques ». (Hugging Face) Exemples : Llama, GPT, Claude, etc.
Pour en savoir plus :
- Hugging Face - Traitement du langage naturel et grands modèles linguistiques
- Qu'est-ce qu'un grand modèle linguistique ?
Comparaison de différentes tâches de traitement du langage naturel (NLP)
Outre la génération, la synthèse et la traduction de contenus textuels, voici quelques-unes des tâches les plus courantes du traitement du langage naturel (NLP) :
- Classification de textes : consiste à attribuer une étiquette à un fragment de texte, par exemple pour déterminer le sentiment exprimé, distinguer un e-mail légitime d'un spam, etc.
- Reconnaissance des entités nommées (NER) : classe chaque mot d'une phrase. Elle identifie les entités prédéfinies dans le texte (nom, personne, lieu, éléments grammaticaux, etc.)
- Réponse à une question (QA) : extrait un passage de texte à partir d'un contexte donné, en réponse à une question formulée en langage naturel.
Le principal problème de la classification de textes réside dans le fait qu'elle ne permet pas d'extraire des données, mais se contente d'attribuer une catégorie. Quant à la reconnaissance d'entités nommées (NER), elle limite les questions que l'on peut poser et les données que l'on peut extraire du règlement de zonage à quelques entités prédéfinies, telles que la hauteur maximale des bâtiments et le pourcentage d'occupation du terrain. Souvent, les règlements de zonage ne fournissent pas de réponse sous forme de valeur numérique unique, et il est difficile de définir clairement les segments d'entités. Par conséquent, la réponse aux questions est considérée comme la méthode la plus appropriée, car elle extrait une portion de texte à partir du contexte donné.
Il existe de nombreux types de modèles LLM pouvant être spécialisés pour des tâches telles que la réponse aux questions. Le choix de l'architecture d'un modèle LLM a une incidence sur la précision, les performances et les ressources.
Les avantages et les inconvénients des différentes architectures de modèles sont présentés ici :
- Modèles de type « encoder only » : idéaux pour comprendre et extraire des informations (par exemple : BERT, Bidirectional Encoder Representations from Transformers). Pas d'« hallucinations », plus rapides, plus légers, entraînés sur des ensembles de données plus petits pour des tâches hautement spécialisées. Ces modèles ne comportent aucune composante générative.
- Modèles de type « décodeur seul » : idéaux pour générer du texte (par exemple : GPT, Generative Pre-Trained Transformer). Peuvent produire des informations erronées, sont plus gourmands en ressources et sont entraînés sur des ensembles de données plus volumineux afin d'offrir une utilisation plus polyvalente.
- Modèles encodeur-décodeur : adaptés à des tâches telles que la traduction ou la synthèse.
Au sein de ces trois types de modèles, il faut ensuite examiner comment ils gèrent le contexte. En d'autres termes, chaque modèle peut traiter des textes d'entrée et de sortie de longueurs différentes. Par exemple, la longueur de votre question est limitée. Étant donné que les règlements de zonage peuvent compter des centaines de pages, la longueur du contexte est un facteur essentiel !
- Modèles à contexte court : plus rapides, moins coûteux, mais les données doivent être divisées en segments pour être intégrées au modèle.
- Modèles à contexte étendu : prennent en charge davantage de contexte et des textes plus longs (idéaux pour les documents juridiques tels que les règlements de zonage), mais sont plus lents et plus coûteux.
Pour en savoir plus :
- Hugging Face – Comment fonctionnent les Transformers ? Approfondissement des concepts d'attention et de l'architecture encodeur-décodeur
- Hugging Face – Comment les Transformers résolvent des tâches
- Hugging Face – Architectures Transformer. En savoir plus sur les trois principales variantes architecturales
Au vu de ces informations, il semble que les modèles basés uniquement sur un encodeur et axés sur la compréhension des phrases, tels que BERT (Bidirectional Encoder Representations from Transformers) et RoBERTa (Robustly Optimized BERT Approach), soient les plus adaptés pour tester l'extraction de données d'urbanisme à partir des règlements de zonage. (Nous reviendrons plus en détail sur ces deux modèles dans la deuxième partie.)
Les avantages de l'utilisation de modèles open source/open weight
Heureusement, bon nombre de ces modèles de base LLM très répandus sont des modèles à paramètres ouverts. Le terme « paramètres ouverts », à l'instar de « open source », signifie qu'ils sont :
- Ils sont gratuits et s'accompagnent de nombreux tutoriels de qualité qui expliquent au grand public comment y accéder et les utiliser.
- Poids ouverts : les poids d'un modèle sont des paramètres appris/numériques qui déterminent l'importance des caractéristiques dans un ensemble de données ou la manière dont les données d'entrée sont transformées en données de sortie. Les poids agissent comme des boutons de réglage qui contrôlent l'influence d'une entrée (image ou texte) sur le résultat final de l'IA. Lors de l'entraînement ou du réglage fin d'un modèle, ces poids sont ajustés à mesure que le modèle apprend à partir des données. Les modèles à poids ouverts signifient que n'importe qui peut voir ces paramètres, télécharger et réutiliser le modèle, ou encore l'entraîner ou le régler finement davantage à ses propres fins. Pour en savoir plus sur les poids des modèles
- Transparence en matière de performances et de précision
- Transparence concernant les données d'entraînement : les modèles à poids ouverts mettent souvent en avant les ensembles de données sur lesquels ils ont été entraînés. Souvent, ces ensembles de données sont eux aussi open source et peuvent être téléchargés par d'autres utilisateurs pour entraîner et affiner leur propre modèle.
Étant donné que les règlements de zonage sont des documents juridiques accessibles au public, il est logique d'utiliser des modèles de données ouverts pour en extraire des informations d'urbanisme !
À suivre dans la deuxième partie !
Maintenant que nous avons sélectionné quelques modèles de langage de grande envergure (LLM) à utiliser, la partie suivante se concentre sur l'évaluation de leur capacité à extraire des informations d'urbanisme des règlements de zonage. Cet article examine en détail les résultats d'une étude de cas comparant la précision de différents modèles LLM. Parmi les thèmes abordés, citons :
- Quels indicateurs d'évaluation pouvons-nous utiliser pour évaluer les modèles de langage à grande échelle (LLM) dans le cadre de cette tâche de réponse à des questions ?
- Choisir le bon indicateur d'évaluation
- Qu'est-ce que Zero Shot ?
- La qualité des données, c'est essentiel ! Comment utiliser les modèles de réponse aux questions et préparer les données pour les alimenter et les évaluer
Ne manquez pas la suite ! Rejoignez le groupe LinkedIn « Planning & Housing » pour être averti dès que la deuxième partie sera mise en ligne.